Publications
Group highlights
For a full list see below or go to Google Scholar. The sign * indicates equal contribution of the authors.
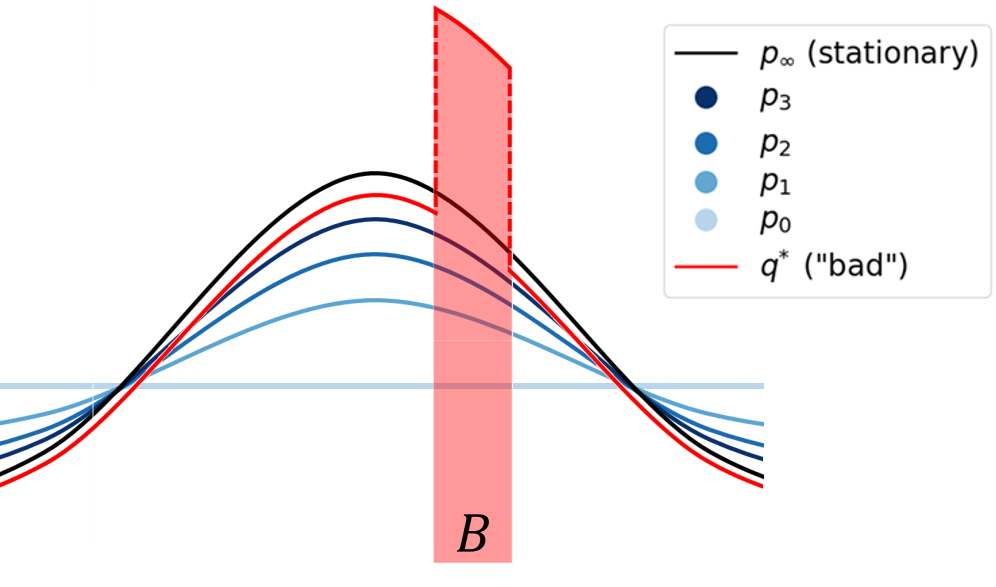
We prove that adding noise to gradient flow leads to a simple yet strong generalization bound.
I. Harel, Y. Wolanowsky, G. Vardi, N. Srebro, D. Soudry

We demonstrate for the first time, fully quantized training of a 7B LLM using FP4 format.
B. Chmiel, M. Fishman, R. Banner, D. Soudry
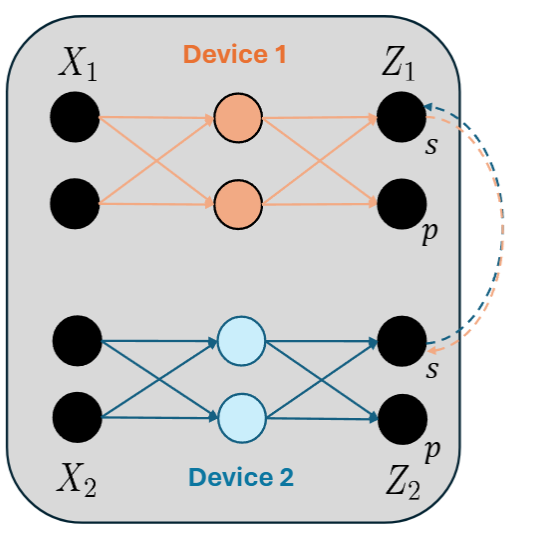
Training LLM’s with tensor-parallelism without completely synchronizing activations to accelerate training and inference, reducing bandwidth by 50%.
I. Lamprecht, A. Karnieli, Y. Hanani, N. Giladi, D. Soudry
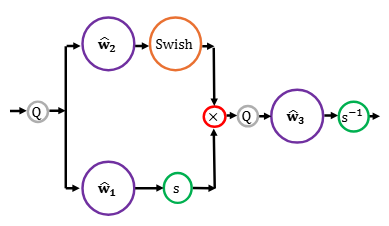
We show how train to LLMs in FP8, even when trained at the scale of trillions of tokens. We analytically and empirically pinpoint the problem in the SwiGLU activation and propose a solution.
M. Fishman, B. Chmiel, R. Banner, D. Soudry
We examine neural networks (NN) with uniform random weights, conditioned on zero training loss. We prove they typically generalize well if there exists an underlying narrow ``teacher NN” that agrees with the labels.
G. Buzaglo *, I. Harel *, M. Shpigel Nacson *, A. Brutzkus, N. Srebro, D. Soudry
ICML 2024 (Spotlight, 3.5% acceptance rate)

We find an analytical relation between compute time properties and scalability limitations, caused by the compute variance of straggling workers in a distributed setting. Then, we propose a simple yet effective decentralized method to reduce the variation among workers and thus improve the robustness of synchronous training.
N. Giladi *, S. Gottlieb * , M. Shkolnik, A. Karnieli, R. Banner, E. Hoffer, K. Y. Levy, D. Soudry
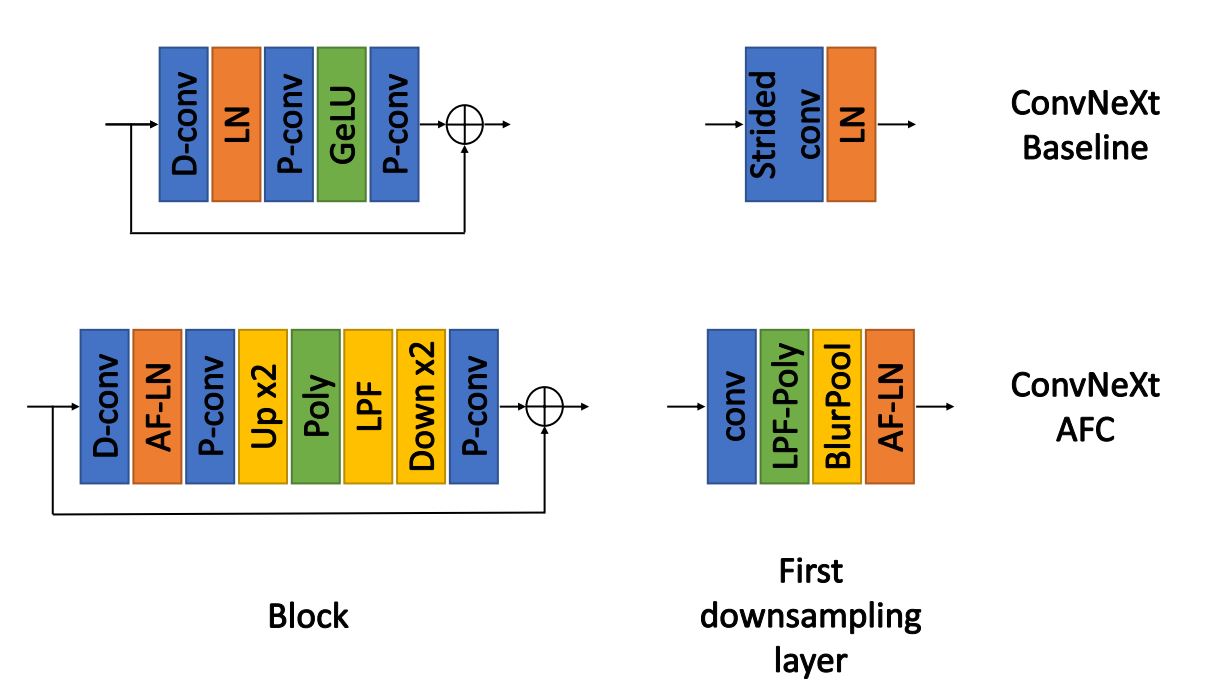
We propose an extended anti-aliasing method that tackles both downsampling and non-linear layers, thus creating truly alias-free, shift-invariant CNNs.
H. Michaeli, T. Michaeli, D. Soudry
See more details about this paper

We study the type of solutions to which stochastic gradient descent converges when used to train a single hidden-layer multivariate ReLU network with the quadratic loss. Our results are based on a dynamical stability analysis.
M. Shpigel Nacson, R. Mulayoff, G. Ongie, T. Michaeli, D. Soudry

Previous works separately showed that accurate 4-bit quantization of the neural gradients needs to (1) be unbiased and (2) have a log scale. However, no previous work aimed to combine both ideas, as we do in this work. Specifically, we examine the importance of having unbiased quantization in quantized neural network training, where to maintain it, and how to combine it with logarithmic.
B. Chmiel, R. Banner, E. Hoffer, H. Ben Yaacov, D. Soudry
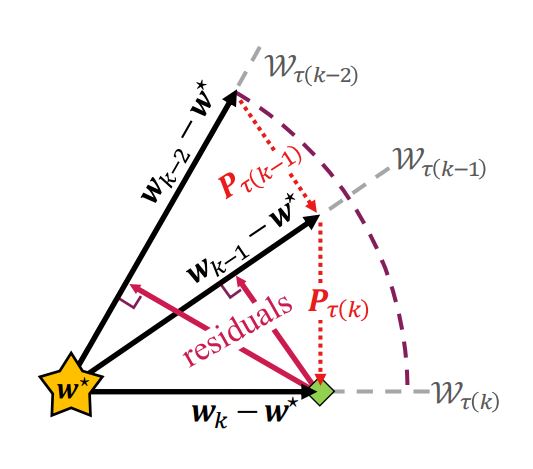
To better understand catastrophic forgetting, we study fitting an overparameterized linear model to a sequence of tasks with different input distributions. We analyze how much the model forgets the true labels of earlier tasks after training on subsequent tasks, obtaining exact expressions and bounds.
I. Evron, E. Moroshko, R. Ward, N. Srebro, D. Soudry

We frame Out Of Distribution (OOD) detection in DNNs as a statistical hypothesis testing problem. Tests generated within our proposed framework combine evidence from the entire network.
M. Haroush, T. Frostig, R. Heller, D. Soudry
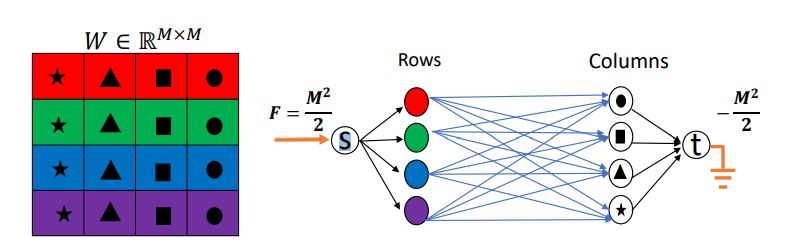
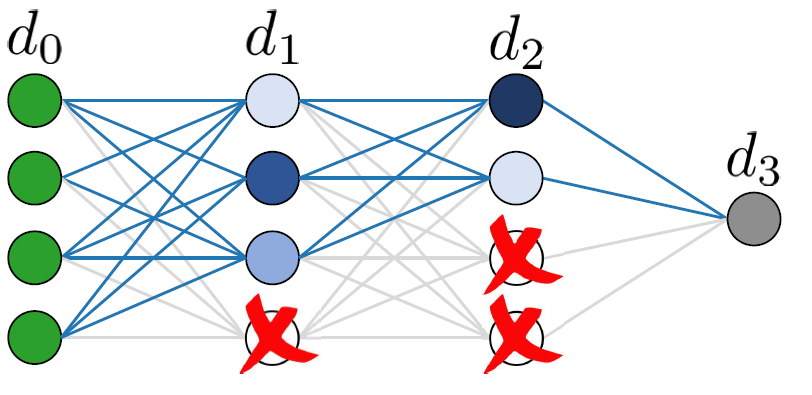
In this work, we first suggest a new measure called mask-diversity which correlates with the expected accuracy of the different types of structural pruning.
I. Hubara, B. Chmiel, M. Island, R. Banner, S. Naor, D. Soudry
See more details about this paper
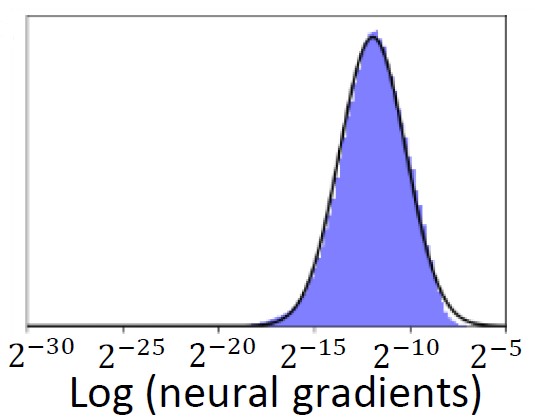
We find that the distribution of neural gradients is approximately lognormal. Considering this, we suggest two closed-form analytical methods to reduce the computational and memory burdens of neural gradients.
B. Chmiel * , L. Ben-Uri * , M. Shkolnik, E. Hoffer, R. Banner, D. Soudry

We provide a detailed asymptotic study of gradient flow trajectories and their implicit optimization bias when minimizing the exponential loss over “diagonal linear networks”. This is the simplest model displaying a transition between “kernel” and non-kernel (“rich” or “active”) regimes.
E. Moroshko, S. Gunasekar, B. Woodworth, J. D. Lee, N. Srebro, D. Soudry
NeurIPS 2020, Spotlight (3% acceptance rate)

Recently, an extensive amount of research has been focused on compressing and accelerating Deep Neural Networks (DNN). So far, high compression rate algorithms require part of the training dataset for a low precision calibration, or a fine-tuning process. However, this requirement is unacceptable when the data is unavailable or contains sensitive information, as in medical and biometric use-cases. We present three methods for generating synthetic samples from trained models.
M. Haroush, I. Hubara, E. Hoffer, D. Soudry

We examine asynchronous training from the perspective of dynamical stability. We find that the degree of delay interacts with the learning rate, to change the set of minima accessible by an asynchronous stochastic gradient descent algorithm. We derive closed-form rules on how the learning rate could be changed, while keeping the accessible set the same.
N. Giladi *, M. Shpigel Nacson *, E. Hoffer, D. Soudry
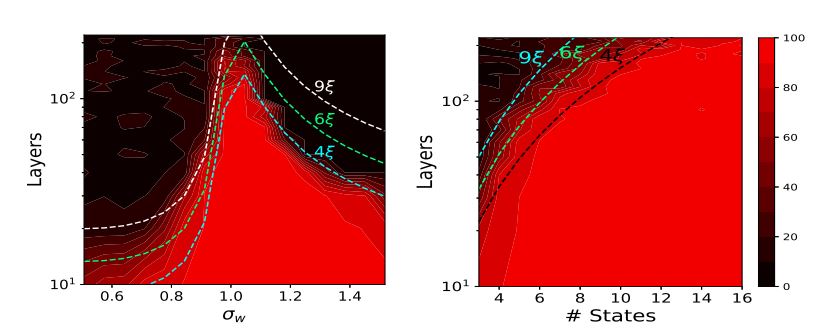
We apply mean-field techniques to networks with quantized activations in order to evaluate the degree to which quantization degrades signal propagation at initialization. We derive initialization schemes which maximize signal propagation in such networks and suggest why this is helpful for generalization.
Y. Blumenfeld, D. Gilboa, D. Soudry
This paper introduces the first practical 4-bit post training quantization approach.
R. Banner, Y. Nahshan, D. Soudry
See more details about this paper
We consider the question of what functions can be captured by ReLU networks with an unbounded number of units (infinite width), but where the overall network Euclidean norm (sum of squares of all weights in the system, except for an unregularized bias term for each unit) is bounded.
P. Savarese, I. Evron, D. Soudry, N. Srebro

Our theoretical analysis suggests that most of the training process is robust to substantial precision reduction, and points to only a few specific operations that require higher precision. Armed with this knowledge, we quantize the model parameters, activations and layer gradients to 8-bit, leaving at a higher precision only the final step in the computation of the weight gradients. Additionally, as QNNs require batch-normalization to be trained at high precision, we introduce Range Batch-Normalization (BN) which has significantly higher tolerance to quantization noise and improved computational complexity.
R. Banner, I. Hubara, E. Hoffer, D. Soudry
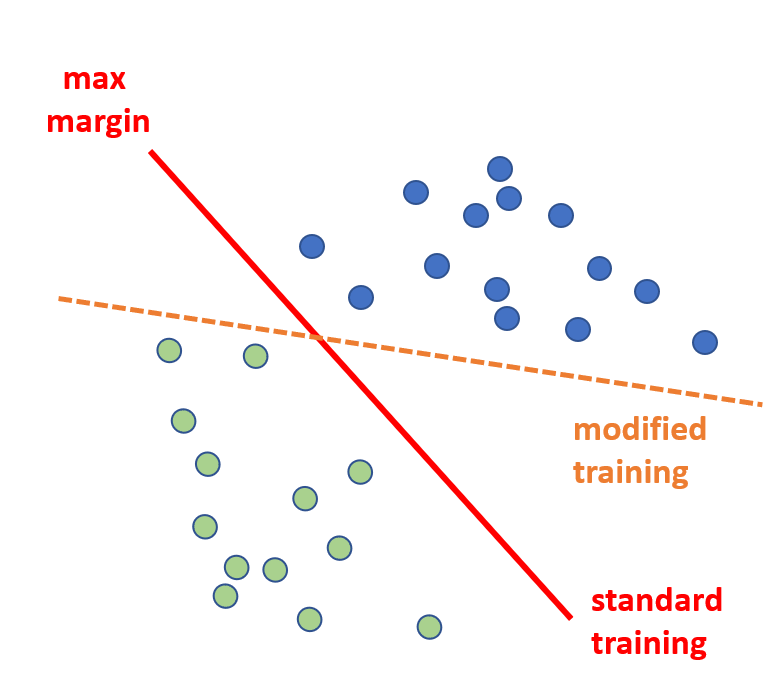
We show that gradient descent on an unregularized logistic regression problem, for almost all separable datasets, converges to the same direction as the max-margin solution. The result generalizes also to other monotone decreasing loss functions with an infimum at infinity, and we also discuss a multi-class generalizations to the cross entropy loss. Furthermore, we show this convergence is very slow, and only logarithmic in the convergence of the loss itself.
D. Soudry , E. Hoffer, M. Shpigel Nacson, N. Srebro
We introduce a method to train Binarized Neural Networks (BNNs) - neural networks with binary weights and activations at run-time. At training-time the binary weights and activations are used for computing the parameters gradients. During the forward pass, BNNs drastically reduce memory size and accesses, and replace most arithmetic operations with bit-wise operations, which is expected to substantially improve power-efficiency.
I. Hubara *, M. Courbariaux *, D. Soudry, R. El-Yaniv, Y. Bengio
Full List of publications
Asterisks over several author names in paper indicate these authors contributed equally to the paper.
Preprints
Block Sparse Flash Attention
D. Ohayon, I. Lamprecht, I. Hubara, I. Cohen, D. Soudry, N. Elata.
arxiv
PLUMAGE: Probabilistic Low rank Unbiased Min Variance Gradient Estimator for Efficient Large Model Training
M. Haroush, D. Soudry
arxiv
Refereed Proceedings
Optimal L2 Regularization in High-dimensional Continual Linear Regression
G. Karpel, E. Moroshko, R. Levinstein, R. Meir, D. Soudry, I. Evron
ALT 2026
From Continual Learning to SGD and Back: Better Rates for Continual Linear Models
I. Evron *, R. Levinstein *, M. Schliserman *, U. Sherman *, T. Koren, D. Soudry, N. Srebro
ALT 2026
Temperature is All You Need for Generalization in Langevin Dynamics and other Markov Processes
I. Harel, Y. Wolanowsky, G. Vardi, N. Srebro, D. Soudry
NeurIPS 2025 (Spotlight)
FP4 All the Way: Fully Quantized Training of LLMs
B. Chmiel, M. Fishman, R. Banner, D. Soudry
NeurIPS 2025 (Spotlight)
Tensor-Parallelism with Partially Synchronized Activations
I. Lamprecht, A. Karnieli, Y. Hanani, N. Giladi, D. Soudry
NeurIPS 2025
Alias-Free ViT: Fractional Shift Invariance via Linear Attention
H. Michaeli, D. Soudry
NeurIPS 2025
Optimal Rates in Continual Linear Regression via Increasing Regularization
R. Levinstein *, A. Attia *, M. Schliserman *, U. Sherman *, T. Koren, D. Soudry, Itay Evron
NeurIPS 2025
Are Greedy Task Orderings Better Than Random in Continual Linear Regression?
M. Tsipory *, R. Levinstein *, I. Evron *, M. Kong *, D. Needell, D. Soudry
NeurIPS 2025
When Diffusion Models Memorize: Inductive Biases in Probability Flow of Minimum-Norm Shallow Neural Nets
C. Zeno, H. Manor, G. Ongie, N. Weinberger, T. Michaeli, D. Soudry
ICML 2025
Scaling FP8 training to trillion-token LLMs
M. Fishman, B. Chmiel, R. Banner, D. Soudry
ICLR 2025 (Spotlight)
Exponential Quantum Communication Advantage in Distributed Inference and Learning
H. Michaeli, D. Gilboa, D. Soudry, J. R. McClean
NeurIPS 2024
Stable Minima Cannot Overfit in Univariate ReLU Networks: Generalization by Large Step Sizes
D. Qiao, K. Zhang, E. Singh, D. Soudry, and Y. X. Wang
NeurIPS 2024 (Spotlight)
Provable Tempered Overfitting of Minimal Nets and Typical Nets
I. Harel, W. M. Hoza, G. Vardi, I, Evron, N. Srebro, D. Soudry
NeurIPS 2024
The Implicit Bias of Gradient Descent on Separable Multiclass Data
H. Ravi, C. Scott, D. Soudry, Y. Wang
NeurIPS 2024
How Uniform Random Weights Induce Non-uniform Bias: Typical Interpolating Neural Networks Generalize with Narrow Teachers
G. Buzaglo *, I. Harel *, M. Shpigel Nacson *, A. Brutzkus, N. Srebro, D. Soudry
ICML 2024 (Spotlight, 3.5% acceptance rate)
Towards Cheaper Inference in Deep Networks with Lower Bit-Width Accumulators
Y. Blumenfeld, I. Hubara, D. Soudry
ICLR 2024
The Joint Effect of Task Similarity and Overparameterization on Catastrophic Forgetting - An Analytical Model
D. Goldfarb *, I. Evron *, N. Weinberger, D. Soudry, P. Hand
ICLR 2024
How do Minimum-Norm Shallow Denoisers Look in Function Space?
C. Zeno, G. Ongie, Y. Blumenfeld, N. Weinberger, D. Soudry
NeurIPS 2023
DropCompute: simple and more robust distributed synchronous training via compute variance reduction
N. Giladi *, S. Gottlieb * , M. Shkolnik, A. Karnieli, R. Banner, E. Hoffer, K. Y. Levy, D. Soudry
NeurIPS 2023
Explore to Generalize in Zero-Shot RL
E. Zisselman, I. Lavie, D. Soudry, A. Tamar
NeurIPS 2023
Gradient Descent Monotonically Decreases the Sharpness of Gradient Flow Solutions in Scalar Networks and Beyond
I Kreisler *, M. Shpigel Nacson *, D. Soudry, Y. Carmon
ICML 2023
Continual Learning in Linear Classification on Separable Data
I. Evron, E. Moroshko, G. Buzaglo, M. Khriesh, B. Marjieh, N. Srebro, D. Soudry
ICML 2023
Alias-Free Convnets: Fractional Shift Invariance via Polynomial Activations
H. Michaeli, T. Michaeli, D. Soudry
CVPR 2023
The Implicit Bias of Minima Stability in Multivariate Shallow ReLU Networks
M. Shpigel Nacson, R. Mulayoff, G. Ongie, T. Michaeli, D. Soudry
ICLR 2023
Minimum Variance Unbiased N:M Sparsity for the Neural Gradients
B. Chmiel, I. Hubara, R. Banner, D. Soudry
ICLR 2023 (“notable top 25%” of accepted papers)
Accurate Neural Training with 4-bit Matrix Multiplications at Standard Formats
B. Chmiel, R. Banner, E. Hoffer, H. Ben Yaacov, D. Soudry
ICLR 2023
The Role of Codeword-to-Class Assignments in Error Correcting Codes: An Empirical Study
I. Evron * , O. Onn * , T. Weiss, H. Azeroual, D. Soudry
AISTAT 2023
How catastrophic can catastrophic forgetting be in linear regression?
I. Evron, E. Moroshko, R. Ward, N. Srebro, D. Soudry
COLT 2022
Implicit Bias of the Step Size in Linear Diagonal Neural Networks
M. Shpigel-Nacson, K. Ravichandran, N. Srebro,D. Soudry
ICML 2022
A Statistical Framework for Efficient Out of Distribution Detection in Deep Neural Networks
M. Haroush, T. Frostig, R. Heller, D. Soudry
ICLR 2022
Regularization Guarantees Generalization in Bayesian Reinforcement Learning through Algorithmic Stability
A. Tamar, D. Soudry, E. Zisselman
AAAI 2022 (15% acceptance rate)
Accelerated Sparse Neural Training: A Provable and Efficient Method to Find N:M Transposable Masks
I. Hubara, B. Chmiel, M. Island, R. Banner, S. Naor, D. Soudry
NeurIPS 2021
Physics-Aware Downsampling with Deep Learning for Scalable Flood Modeling
N. Giladi, Z. Ben-Haim, S. Nevo, Y. Matias,D. Soudry
NeurIPS 2021
The Implicit Bias of Minima Stability: A View from Function Space
R. Mulayoff, T. Michaeli, D. Soudry
NeurIPS 2021
On the Implicit Bias of Initialization Shape: Beyond Infinitesimal Mirror Descent
S. Azulay, E. Moroshko, M. Shpigel Nacson, B. Woodworth, N. Srebro, A. Globerson, D. Soudry
ICML 2021, Long talk (3% acceptance rate).
Accurate Post Training Quantization With Small Calibration Sets
I. Hubara * , Y. Nahshan * , Y. Hanani*, R. Banner, D. Soudry
ICML 2021
Neural gradients are near-lognormal: understanding sparse and quantized training
B. Chmiel * , L. Ben-Uri * , M. Shkolnik, E. Hoffer, R. Banner, D. Soudry
ICLR 2021
Implicit Bias in Deep Linear Classification: Initialization Scale vs Training Accuracy
E. Moroshko, S. Gunasekar, B. Woodworth, J. D. Lee, N. Srebro, D. Soudry
NeurIPS 2020, Spotlight (3% acceptance rate)
Beyond Signal Propagation: Is Feature Diversity Necessary in Deep Neural Network Initialization?
Y. Blumenfeld, D. Gilboa, D. Soudry
ICML 2020
Kernel and Rich Regimes in Overparametrized Models
B. Woodworth, S. Gunasekar, P. Savarese, E. Moroshko, I. Golan, J. Lee, D. Soudry, N. Srebro
COLT 2020
The Knowledge Within: Methods for Data-Free Model Compression
M. Haroush, I. Hubara, E. Hoffer, D. Soudry
CVPR 2020
Augment Your Batch: Improving Generalization Through Instance Repetition
E. Hoffer, T. Ben-Nun, N. Giladi, I. Hubara, T. Hoefler, D. Soudry
CVPR 2020
At Stability’s Edge: How to Adjust Hyperparameters to Preserve Minima Selection in Asynchronous Training of Neural Networks?
N. Giladi *, M. Shpigel Nacson *, E. Hoffer, D. Soudry
ICLR 2020
A Function Space View of Bounded Norm Infinite Width ReLU Nets: The Multivariate Case
G. Ongie, R. Willett, D. Soudry, N. Srebro
ICLR 2020
A Mean Field Theory of Quantized Deep Networks: The Quantization-Depth Trade-Off
Y. Blumenfeld, D. Gilboa, D. Soudry
NeurIPS 2019
Post-training 4-bit quantization of convolution networks for rapid-deployment
R. Banner, Y. Nahshan, D. Soudry
NeurIPS 2019
Lexicographic and Depth-Sensitive Margins in Homogeneous and Non-Homogeneous Deep Models
M. Shpigel Nacson, S. Gunasekar, J. Lee, N. Srebro, D. Soudry
ICML 2019
How do infinite width bounded norm networks look in function space?
P. Savarese, I. Evron, D. Soudry, N. Srebro
COLT 2019
Convergence of Gradient Descent on Separable Data
M. Shpigel Nacson, J. Lee, S. Gunasekar, N. Srebro, D. Soudry
AISTATS 2019, Oral Presentation (2.5% acceptance rate).
Stochastic Gradient Descent on Separable Data: Exact Convergence with a Fixed Learning Rate
M. Shpigel Nacson, N. Srebro, D. Soudry
AISTATS 2019
Norm matters: efficient and accurate normalization schemes in deep networks
E. Hoffer * , R. Banner * , I. Golan * , D. Soudry
NeurIPS 2018, Spotlight (3.5% acceptance rate)
Implicit Bias of Gradient Descent on Linear Convolutional Networks
S. Gunasekar, J. D. Lee, D. Soudry, N. Srebro
NeurIPS 2018
Scalable Methods for 8-bit Training of Neural Networks
R. Banner, I. Hubara, E. Hoffer, D. Soudry
NeurIPS 2018
Characterizing Implicit Bias in Terms of Optimization Geometry
S. Gunasekar, J. Lee, D. Soudry, N. Srebro
ICML 2018
The Implicit Bias of Gradient Descent on Separable Data
D. Soudry , E. Hoffer, M. Shpigel Nacson, N. Srebro
ICLR 2018
Fix your classifier: the marginal value of training the last weight layer
E. Hoffer, I. Hubara, D. Soudry
ICLR 2018
Train longer, generalize better: closing the generalization gap in large batch training of neural networks
E. Hoffer * , I. Hubara * , D. Soudry
NIPS 2017, Oral presentation (1.2% acceptance rate)
Binarized Neural Networks
I. Hubara *, M. Courbariaux *, D. Soudry, R. El-Yaniv, Y. Bengio
NIPS 2016
A Fully Analog Memristor-Based Multilayer Neural Network with Online Backpropagation Training
S. Greshnikov, E. Rosenthal, D. Soudry, and S. Kvatinsky
Proceeding of the IEEE International Conference on Circuits and Systems 2016
Expectation Backpropagation: Parameter-Free Training of Multilayer Neural Networks with Continuous Or Discrete Weights
D. Soudry , I. Hubara and R. Meir
NIPS 2014
Neuronal spike generation mechanism as an oversampling, noise-shaping A-to-D converter
D. B. Chklovskii and D. Soudry
NIPS 2012
Journal Papers
Foldable SuperNets: Scalable Merging of Transformers with Different Initializations and Tasks
E. Kinderman, I. Hubara, H. Maron, D. Soudry
TMLR, 2025
Training of Quantized Deep Neural Networks using a Magnetic Tunnel Junction-Based Synapse
T. Greenberg-Toledo, B. Perach, I. Hubara, D. Soudry, S. Kvatinsky
Semiconductor Science and Technology, 2021
Task Agnostic Continual Learning Using Online Variational Bayes with Fixed-Point Updates
C. Zeno *, I. Golan *, E. Hoffer, D. Soudry
Neural Computation, 2021
The Global Optimization Geometry of Shallow Linear Neural Networks
Z. Zhu, D. Soudry, Y. C. Eldar, M. B. Wakin
Journal of Mathematical Imaging and Vision, 2019
Seizure pathways: A model-based investigation
P. J. Karoly, L. Kuhlmann, D. Soudry, D. B. Grayden, M. J. Cook, D. R. Freestone
PLoS Comput Biol., vol. 14 no. 10, e1006403, 2018
The Implicit Bias of Gradient Descent on Separable Data
D. Soudry , E. Hoffer, M. Shpigel Nacson, S. Gunasekar, N. Srebro
JMLR, 2018
Bifurcation Analysis of Two Coupled Jansen-Rit Neural Mass Models
S. Ahmadizadeh, P. Jane Karoly, D. Nesic, D. Br. Grayden, M. J.Cook, D. Soudry, D. R. Freestone
PLOS One, vol. 13 no. 3, e0192842, 2018
Quantized Neural Networks: Training Neural Networks with Low Precision Weights and Activations
I. Hubara * , M. Courbariaux * ,D. Soudry, R. El-Yaniv, Y. Bengio.
JMLR, 2018
Multi-scale approaches for high-speed imaging and analysis of large neural populations
J. Friedrich, W. Yang, D. Soudry, Y. Mu, M. B. Ahrens, R. Yuste, D. S. Peterka, L. Paninski
PLos Comput Biol, vol., 13 no. 8, e1005685, 2017
Extracting grid cell characteristics from place cell inputs using non-negative principal component analysis
Y. Dordek *, D. Soudry *, R. Meir, D. Derdikman
eLife, vol. 5, e10094, 2016
Simultaneous Denoising, Deconvolution, and Demixing of Calcium Imaging Data
E. A. Pnevmatikakis, D. Soudry, Y. Gao, T. A. Machado, J. Merel, D. Pfau,T. Reardon,Y. Mu, C. Lacefield, W. Yang, M. Ahrens, R. Bruno, T. M. Jessell, D. S. Peterka, R. Yuste, L. Paninski,
Neuron, vol. 89, no. 2, 2016
Efficient ‘Shotgun’ Inference of Neural Connectivity from Highly Sub-sampled Activity Data
D. Soudry , S. Keshri, P. Stinson, M.H. Oh, G. Iyengar, L. Paninski
PLoS Comput Biol, vol. 11, no. 10, 2015
Memristor-based multilayer neural networks with online gradient descent training
D. Soudry , D. Di Castro, A. Gal, A. Kolodny, and S. Kvatinsky
IEEE TNNLS, vol. 26, no. 10, 2015
Diffusion approximation-based simulation of stochastic ion channels: which method to use?
D. Pezo, D. Soudry, P. Orio
Front. Comput. Neurosci., vol. 8, no. 139, 2014
The neuronal response at extended timescales: a linearized spiking input-output relation
D. Soudry and R. Meir
Front. Comput. Neurosci., vol. 8, no. 29, 2014
The neuronal response at extended timescales: long term correlations without long memory
D. Soudry and R. Meir
Front. Comput. Neurosci., vol. 8, no. 35, 2014
Simple, fast and accurate implementation of the diffusion approximation algorithm for stochastic ion channels with multiple states
P. Orio and D. Soudry
PLoS ONE, vol. 7, no. 5 p. e36670, 2012
Conductance-based neuron models and the slow dynamics of excitability
D. Soudry and R. Meir
Front. Comput. Neurosci., vol. 6, no. 4, 2012
History-Dependent Dynamics in a Generic Model of Ion Channels–An Analytic Study
D. Soudry and R. Meir
Front. Comput. Neurosci., vol. 4, Jan. 2010
Patents
I. Hubara, D. Soudry, and R. El-Yaniv,
Binarized Neural Networks
US Patent 10,831,444 (2020)
D. Soudry, D. Di Castro, A. Gal, A. Kolodny, and S. Kvatinsky
Analog Multiplier Using Memristor a Memristive Device and Methods for Implementing Hebbian Learning Rules Using Memristor Arrays
US Patent US9754203 B2 (2016)
3. T. Greenberg-Toledo, D. Soudry, S. Kvatinsky
MTJ-Based Hardware Synapse Implementation for Ternary and Binary Deep Neural Networks
US Patent 12,182,690 (2024)
Refereed Abstracts (Conferences, Symposia, and Workshops)
Why Cold Posteriors? On the Suboptimal Generalization of Optimal Bayes Estimates
C. Zeno, I. Golan, A. Pakman, D. Soudry
Third Symposium on Advances in Approximate Bayesian Inference, contributed talk (2021).
How Learning Rate and Delay Affect Minima Selection in Asynchronous Training of Neural Networks: Toward Closing the Generalization Gap (Oral)
N. Giladi * , Mor Shpigel * , E. Hoffer, D. Soudry
ICML ‘Understanding and Improving Generalization in Deep Learning’ workshop (2019)
A Mean Field Theory of Quantized Deep Networks: The Quantization-Depth Trade-Off (Oral)
Y. Blumenfeld, D. Gilboa, D. Soudry
ICML ‘Physics for deep learning’ workshop (2019)
Increasing batch size through instance repetition improves generalization (Poster)
E. Hoffer, T. Ben-Nun, N. Giladi, I. Hubara, T. Hoefler, D. Soudry
ICML ‘Understanding and Improving Generalization in Deep Learning’ workshop, poster (2019)
Task Agnostic Continual Learning Using Online Variational Bayes (Poster)
C. Zeno *, I. Golan *, E. Hoffer, D. Soudry
NIPS Deep Bayesian learning workshop, 2018
Infer2Train: leveraging inference for better training of deep networks (Poster)
E Hoffer, B Weinstein, I Hubara, S Gofman, D Soudry
NIPS Deep Bayesian learning workshop, 2018
Exponentially vanishing sub-optimal local minima in multilayer neural networks (Poster)
D. Soudry, E. Hoffer
ICLR workshop, 2018
Quantized Neural Networks (Poster)
I. Hubara * , M. Courbariaux *, D. Soudry, R. El-Yaniv, Y. Bengio
NIPS workshop on Efficient Methods for Deep Neural Networks (2016)
Quantized Neural Networks (Poster)
I. Hubara * , M. Courbariaux *, D. Soudry, R. El-Yaniv, Y. Bengio
NIPS workshop on Efficient Methods for Deep Neural Networks (2016)
Binarized neural networks (Poster)
I. Hubara * , M. Courbariaux *, D. Soudry, R. El-Yaniv, Y. Bengio
Machine Learning seminar, IBM research center, Haifa (2016)
Data-driven neural models part II: connectivity patterns of human seizures (Best student poster)
P. J. Karoly, D. R. Freestone, D. Soudry, L. Kuhlmann, L. Paninski, M. Cook
CNS (2016)
Data-driven neural models part I: state and parameter estimation (Poster)
D. R. Freestone, P. J. Karoly, D. Soudry, L. Kuhlmann, M.Cook
CNS (2016)
Extracting grid characteristics from spatially distributed place cell inputs using non-negative PCA (Poster)
Y. Dordek * , D. Soudry * , R. Meir, D. Derdikman
SFN (2015)
Fast Constrained Non-negative Matrix Factorization for Whole-Brain Calcium Imaging Data (Poster)
J. Friedrich, D. Soudry, Y. Mu, J. Freeman, M. Ahrens, and L. Paninski
NIPS workshop on Statistical Methods for Understanding Neural Systems (2015)
Implementing efficient ‘shotgun’ inference of neural connectivity from highly sub-sampled activity data (Spotlight Presentation and poster)
D. Soudry , S. Keshri, P. Stinson, M.H. Oh, G. Iyengar, L. Paninski
NIPS workshop on Modelling and Inference for Dynamics on Complex Interaction Networks (2015)
Expectation Backpropagation: Parameter-Free Training of Multilayer Neural Networks with Continuous Or Discrete Weights (Poster)
D. Soudry ,I. Hubara and R. Meir
Machine Learning seminar (IBM research center, Haifa 2015)
Efficient “shotgun” inference of neural connectivity from highly sub-sampled activity data (Oral)”
D. Soudry , S. Keshri, P. Stinson, M.H. Oh, G. Iyengar, L. Paninski
Swartz Annual Meeting at Janelia Research Campus (2015)
A shotgun sampling solution for the common input problem in neural connectivity inference (Poster)
D. Soudry , S. Keshri, P. Stinson, M.H. Oh, G. Iyengar, L. Paninski
COSYNE (2015)
Whole Brain Region of Interest Detection (Poster)
D. Pfau *, D. Soudry *, Y. Gao, Y. Mu, J. Freeman, M. Ahrens, L. Paninski
NIPS workshop on Large scale optical physiology -From data-acquisition to models of neural coding (2014)
Whole Brain Region of Interest Detection (Poster)
D. Pfau , D. Soudry , Y. Gao, Y. Mu, J. Freeman, M. Ahrens, L. Paninski
AREADNE (2014)
Mean Field Bayes Backpropagation: scalable training of multilayer neural networks with discrete weights (Poster)
D. Soudry and R. Meir
Machine Learning seminar (IBM research center, Haifa 2013)
Implementing Hebbian Learning Rules with Memristors (Poster)
D. Soudr y, D. Di Castro, A. Gal, A. Kolodny, and S. Kvatinsky
Memristor-based Systems for Neuromorphic Applications (Torino University 2013)
A spiking input-output relation for general biophysical neuron models explains observed 1/f response (Poster)
D. Soudry and R. Meir
COSYNE (2013)
Spiking input-output relation of general biophysical neuron models – exact analytic solutions and comparisons with experiment (Poster)
D. Soudry and R. Meir
Variants and invariants in brain and behavior (Technion 2012)
The slow dynamics of neuronal excitability - exact analytic solutions for the response of general biophysical neuron models at long times, and comparisons with experiment (Poster)
D. Soudry and R. Meir
Brain Plasticity Symposium (Tel Aviv university 2012)
The slow dynamics of neuronal excitability (Poster)
D. Soudry and R. Meir
ISFN (2012)
The neuron as a population of ion channels: The emergence of stochastic and history dependent behavior (Poster)
D. Soudry and R. Meir
COSYNE (2011)
The neuron as a population of ion channels: The emergence of stochastic and history dependent behavior (Oral)
D. Soudry and R. Meir
ISFN (2010)
History dependent dynamics in ion channels - an analytic study (Poster)
D. Soudry and R. Meir
COSYNE (2010)
Adapting Timescales: From Channel to Neuron” (Oral)
D. Soudry and R. Meir
ISFN (2009)
Notes
Mix & Match: training convnets with mixed image sizes for improved accuracy, speed and scale resiliency
E. Hoffer, B. Weinstein, I. Hubara, T. Ben-Nun, T. Hoefler, D. Soudry
See Here
On the Blindspots of Convolutional Networks
E. Hoffer, S. Fine, D. Soudry
See Here
No bad local minima: Data independent training error guarantees for multilayer neural networks
D. Soudry , Y. Carmon
See Here